[Ref] CS 231 Lecture
안녕하세요. 이번 포스팅에서는 Recurrent Neural Network, RNN에 대해서 배워보도록 하겠습니다.
RNN의 등장 배경을 먼저 알아보도록 하겠습니다.
기존의 MLP 나 CNN은 좋은 성능을 보여주지만, 한 가지 전제 가정을 가지고 있습니다.
그것을 바로, MLP의 경우 모든 Inputs들이 서로 독립이라는 가정을 하며, CNN의 경우에는 모든 2D input들이 input내에서는 locally correlated 한 관계를 가지지만, 서로 다른 이미지간에는 독립이라는 가정이 있습니다.
하지만, 실제로 Vidio에서 앞 장면과 뒷 장면은 전혀 독립이지 않습니다. 그리고, 문장 안에서 앞 뒤의 단어는 독립이 아니고, correlation이 상당히 존재합니다.
예를 들어서, 아래와 같은 사진이 Input으로 들어왔다고 가정합시다.

이 사진에 대한 설명을 하라고, 컴퓨터에 학습을 시키면 "잠만보가 샤워를 하고 있다" 라고 해석이 됩니다.
하지만, 사실 앞장면에는 다음과 같은 장면이 있습니다.

즉, 실제로 잠만보는 킹드라에게 공격을 받고 있던것이지요. 즉, 사진 사이에 독립이 아니고, 상관성이 존재한다는 것입니다.
따라서, 이전 input들과 현재 input을 둘 다 고려한 방법으로 RNN이 등장하게 되었습니다.


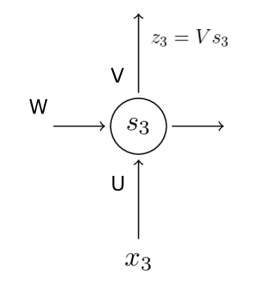
RNN의 기본구조는 위와 같습니다.
RNN에서는 U,V,W 3개의 Weight가 존재합니다.

st 를 계산하는 과정에서 이전 값인 st-1 포함되기 때문에, memory 의 기능을 하게 됩니다.
이 때, f는 비선형 함수를 사용합니다. 주로 tanh가 많이 사용됩니다.
RNN의 구조를 도식화하면 아래와 같습니다.

과거의 정보는 h 에 계속 저장이 되며, 새로운 인풋 x에 의해 업데이트가 됩니다. 그리고, 업데이트가 되면서 output도 하나씩 나오게 되므로, 오차를 계산할 수 있습니다.

하지만 위와 같이 모든 오차를 고려하여, backpropogation을 하면, 시간 및 계산 비용도 엄청나지만, Long-term dependency 문제가 발생합니다. Long-term dependency는 문제는 쉽게 말해서, RNN이 깊어지면, 저 멀리 과거의 정보는 반영이 거의 되지 않는다는 것입니다.
왜그런지를 알기위해서는, RNN의 학습과정을 살펴봐야 합니다.

위와 같은 RNN 구조에서 U,W,V를 학습해도록 하겠습니다.
U,W,V는 각각 오차를 최소화 하는 방향으로 업데이트 됩니다. (Backproporgation)

E3 에 대한 부분만 따로 때서 계산해보도록 하겠습니다.
이 때, 오차함수는 MSE, 그리고, y를 예측하는 함수로 linear 함수를 사용한다고 가정해보도록 하겠습니다.

E3 에 대한 W의 업데이트의 식에 계속 곱해지는 부분이 있는데, 하지만 저 곱하는 부분이 tanh를 미분한 값이기 때문에, 1과 -1 사이에 위치하는 값입니다. 즉, 저 값들을 계속 곱하다보면, 0에 수렴하여 k=0, 즉 가장 앞부분에서 얻는 영향이 거의 없다는 것이지요.
이러한 문제점을 해결하기 위해 나온 RNN이 LSTM입니다.
LSTM은 다음 포스팅에서 배워보도록 하겠습니다.
'데이터 다루기 > 신경망' 카테고리의 다른 글
| [신경망] 20. Long Short Term Memory (LSTM) (0) | 2019.06.18 |
|---|---|
| [신경망] 18. Deconvolution (0) | 2019.06.18 |
| [신경망] 17. Transfer Learning (1) | 2019.06.18 |
| [신경망] 16. CNN Architecture (2) VGGNet, GoogleNet (0) | 2019.06.04 |
| [신경망] 15. CNN Architecture (1) AlexNet, ZFNet (0) | 2019.06.04 |



