728x90
안녕하세요, 이번 포스팅에서는 가장 유명한 앙상블 기법인 랜덤 포레스트 (Random Forest)에 대해서 배워보도록 하겠습니다.
랜덤 포레스트는 배깅에서 약간 변화된 방법의 일종이면서, Base Learner로써 의사결정 나무를 사용합니다.
랜덤 포레스트와 배깅의 차이점은, 배깅은 데이터를 랜덤 추출해서 사용하지만, 랜덤포레스트는 x, 즉 독립변수를 랜덤추출해서 사용합니다.
분류문제의 경우 p개의 독립변수에서 sqrt(p) 개를 랜덤하게 추출해서 사용하며, 회귀문제에서는 p/3개의 독립변수를 추출해서 사용하는 것을 권장하고 있습니다.
그림으로 보기 쉽게 도식화하면 다음과 같습니다.
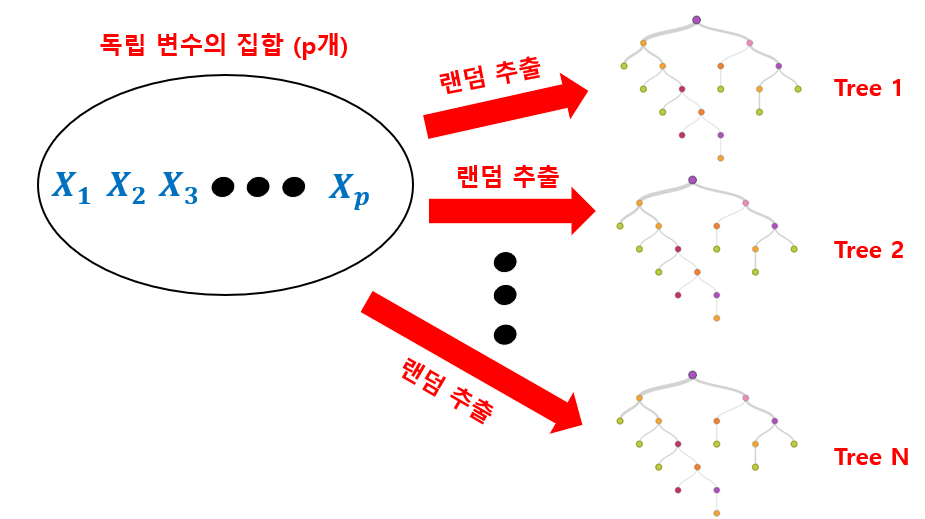
모든 X를 다 사용하지 않고, 몇개만 사용하는 알고리즘인데 과연 이게 좋을까? 싶지만 실제로 랜덤 포레스트를 사용해보신분들을 알겠지만, 성능이 다른 모델들에 비해서 상당히 좋은 편입니다.
'데이터 다루기 > 머신러닝 이론' 카테고리의 다른 글
| [머신러닝] Minimum-redundancy-maximum-relevance (mRMR) (1) | 2019.07.03 |
|---|---|
| [머신러닝] Feature Selection (0) | 2019.07.03 |
| [머신러닝] Ensemble Learning (4) Stacking (0) | 2019.07.02 |
| [머신러닝] Ensemble Learning (3) Boosting (AdaBoost) (0) | 2019.07.02 |
| [머신러닝] Ensemble Learning (2) Bagging (0) | 2019.07.02 |



