1. 머신러닝의 정의
머신러닝 (Machine Learning)은 위키피디아의 정의에 따르면
"컴퓨터 시스템이 대신 패턴과 추론에 의존하면서 명시적 지시를 사용하지 않고 특정 작업을 효과적으로 수행하기 위해 사용하는 알고리즘과 통계 모델의 과학적 연구" 라고 나타나있다.
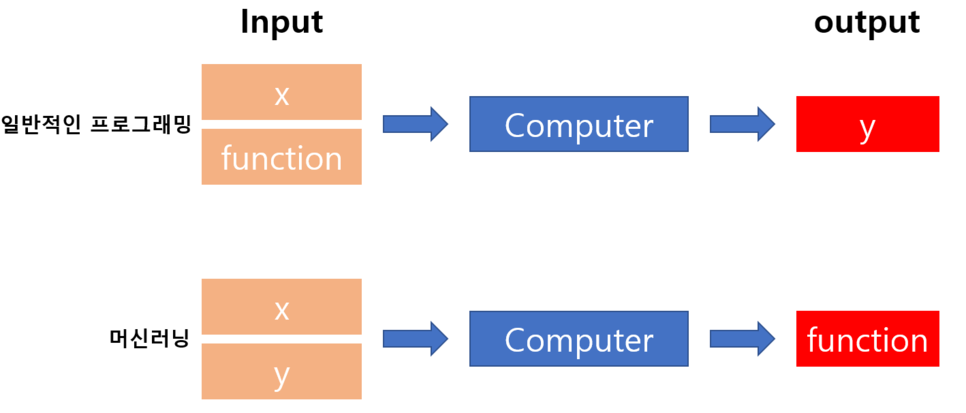
즉 쉽게 말해서, 이전에 우리가 수학에서 배워오던 익숙한 과정은 input 변수 x와 function f(x)가 주어지고, output: y=f(x)를 얻는 것이였지만, 머신러닝은 input 변수 x와 output 변수 y가 주어지고, 그 관계를 나타내는 Target function: f()를 찾는 일련의 과정이라 할 수 있다.
input 변수와 output 변수간의 관계는 오차값 ε 와 함께 다음과 같이 표현된다.
y = f(x) + ε
이 때 y 값이 실수 (Real number) 인 경우, 회귀모형이라고 정의되며, y값이 범주형 (categorical value) 인 경우, 분류모형이라고 정의됩니다.
2. 머신러닝의 구성요소
머신러닝은 크게 3가지 요소로 구성됩니다.
① Representation
- 지식을 표현하는 방법에 대한 요소입니다. 예를 들어서, 선형회귀모형, 의사결정나무, 연관규칙, 서포트 벡터 머신 등의 방법이 이에 속한다고 할 수 있습니다.
② Evaluation
- Representation 단계에서 사용된 방법에 대하여 평가를 하는 요소입니다. 예를 들어서, Accuracy, Squared Error, Likeliwood, Cost 등이 속한다고 할 수 있습니다.
③ Optimization
- Evaluation 단계에서 얻은 결과를 바탕으로 Representation 단계에서 사용된 방법을 최적화 하는 요소입니다. 예를 들어서, combinatorial optimization, convex optimization, constrained optimization 등이 속한다고 할 수 있습니다.
3. 머신러닝의 기본적인 알고리즘
머신러닝의 알고리즘은 크게 5가지 단계로 진행됩니다.

① 도메인 파악 및 우선순위 정하기
- 도메인 전문가에게서 지식을 얻고, 머신러닝을 통해서 얻고자 하는 목표의 우선순위를 정합니다.
② 데이터 수집 및 전처리
- 필요한 데이터를 수집하고, 사용할 변수 선택, 이상치 제거, Null값 제거 등의 과정을 거쳐 dirty한 Raw data를 분석의 목적에 맞게 바꾸는 전처리 과정을 진행합니다.
- 머신러닝 알고리즘 중에서 가장 시간이 많이 필요한 단계이며, 분석 결과에 중대한 영향을 미치는 중요한 과정입니다.
③ 모델링
(1) 모델 선택: 분석의 목적에 맞는 적절한 모델을 선택합니다. (범주형 y에는 분류모형을, 연속형 y에는 회귀모형을 선택)
(2) 변수 선택: 너무 많은 변수는 결과 해석을 모호하게 만들 수 있으므로, 필요한 변수만을 선택합니다.
(3) 모형 향상: 필요한 경우 모델의 성능을 향상시키기 위한 방법을 적용합니다.
④ 결과 해석
- 전 단계에서 나온 결과를 분석 목적에 맞게 해석하는 단계입니다. 이 단계에서 도메인 지식이 중요하게 작용합니다.
⑤ 발견된 지식 정리
- 해석된 결과를 정리하며 마무리하는 단계입니다.
'데이터 다루기 > 머신러닝 이론' 카테고리의 다른 글
| [머신러닝] 선형 회귀 분석 (1) (0) | 2019.06.11 |
|---|---|
| 모델 평가 (1) | 2019.06.11 |
| Bias & Variance Trade-off (0) | 2019.06.11 |
| Reducible and Irreducible Errors (0) | 2019.06.10 |
| 머신러닝 vs 데이터마이닝 (0) | 2019.06.10 |


