안녕하세요, 오늘은 머신러닝에서 Bias term 과 variance term의 트레이드 오프 관계에 대해서 알려드리겠습니다.
Bias는 우리가 적합한 머신러닝 모델이 실제값과 얼마나 닮았는가를 나타내는 지표입니다. 영어로는 goodness-of-fit라고 말하기도 합니다.
반면에, variance는 모델이 우리가 훈련 시킨 데이터 셋 이외의 데이터 셋에도 얼마나 잘 들어맞는지에 대한 지표입니다. variance는 일반적으로 모델이 복잡해질수록 높아지는 성향이 있습니다.

위의 그림이 Bias와 Variance에 대해 시각적으로 표현 해줍니다. 1번 그림같은 경우는 모델이 매우 심플하기 때문에 variance는 작지만, 실제값과 모델간의 차이가 상당하므로 높은 bias를 가지고 있다고 할 수 있습니다. 우리는 이러한 경우를 underfitting가 되었다고 할 수 있습니다. 하지만 3번 그림같은 경우는 모델이 실제값과 매우 잘 적합하여 낮은 bias를 가지지만, 모델이 상당히 복잡하여 높은 variance를 가진다고 할 수 있습니다. 이러한 경우는 overfitting이 되었다고 할 수 있습니다.

가장 이상적인 모델은 Low Bias와 Low Variance를 가지는 것이지만, 하지만 실제로 이러한 상황은 거의 나타나지 않습니다.

위의 그림처럼 bias와 variance 사이에는 트레이드 오프 관계가 존재하기 때문에, underfitting 과 overfitting을 최소화 할 수 있는 최적의 모델을 찾는것이 목표입니다.
그러면 이제 Bias와 Variance를 수식으로 나타내보겠습니다.
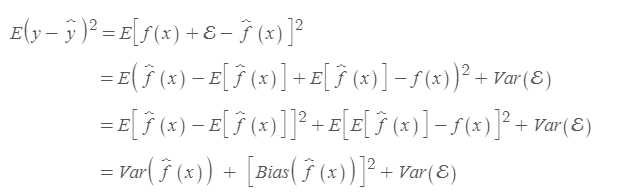
이 때 앞 포스팅에서 살펴본 error 식과의 차이점은 앞에서는 x가 정해져있기 때문에 기댓값에서 바로 빠져나왔지만, 지금 경우에는 데이터가 정해지지 않고 바뀔수 있기 때문에 확률변수로 취급됩니다.
이 때 f(x)가 복잡할수록 더 많은 데이터를 포착할 수 있기 때문에 Bias가 작아지지만, 각 점을 포착하기 위해 더 많이 움직여야 하므로 Variance가 커진다고 생각하시면 이해하시는데 어려움이 없으실것입니다.
'데이터 다루기 > 머신러닝 이론' 카테고리의 다른 글
| [머신러닝] 선형 회귀 분석 (1) (0) | 2019.06.11 |
|---|---|
| 모델 평가 (1) | 2019.06.11 |
| Reducible and Irreducible Errors (0) | 2019.06.10 |
| 머신러닝 vs 데이터마이닝 (0) | 2019.06.10 |
| 머신러닝이란? (0) | 2019.06.10 |


