안녕하세요, 오늘은 저희가 적합한 머신러능 모델의 평가 방법에 대해서 알려드리도록 하겠습니다.
1. 성능 평가 방법
우선 모델평가 방법은 저희가 가지고 있는 데이터의 숫자가 적을 때와 많을 때 두가지로 나뉜다고 할 수 있습니다.
데이터의 개수가 많을 때는 Data set을 쪼깸으로써 평가를 진행합니다.

위의 그림처럼 데이터셋을 Train set, Validation set, Test set으로 나눌 수 있습니다.
① Train set
Train 데이터 셋은 모델을 훈련시킬 때 사용됩니다. 이 때 모델을 너무 복잡하게 만든다면 앞에서 배웠다시피 overfitting이 발생할 수 있으니 유의해야합니다.
② Validation set
Validation 데이터 셋은 우리가 Train set에서 적합한 모델의 parameter (ex : neural network 의 히든노드 개수)를 수정하거나, overfitting 여부를 확인하는데 사용됩니다.
③ Test set
Test 데이터 셋은 우리가 앞서 적합한 모델의 성능을 평가하는데 사용됩니다.
일반적으로 Train set, Validation set, Test set 으로 나누는 비율은 7:1.5:1.5로 나누게 됩니다.
상황에 따라 Validation set 없이 Train set, Test set 만 7:3으로 나누기도 합니다.
다음으로 데이터의 수가 적다면, 데이터 분할이 좋은 방법이 아닐 수 있습니다.
이에 대한 대안으로 여러가지 방법의 모델 평가 방법이 존재합니다.
① k-fold cross validation

데이터 셋을 k개로 분할한 후 k 개의 데이터 조각중에서 k-1개를 Train set으로 지정하고 남은 한 개의 데이터 조각을 Test set으로 지정하여 학습하는 방법입니다. 위 그림의 예시대로 k=5일 때 데이터를 5조각으로 쪼갠후에 4개의 Train set, 1개의 Test set으로 지정하여 모델을 평가합니다. 이 때 모든 데이터 조각들은 한번씩 Test set이 되서 평가가 되야하므로 모델은 5번 평가되는 것을 확인할 수 있습니다. 5번의 평가 후 평가 지표의 평균을 결과로 정합니다.
② Bootstrapping
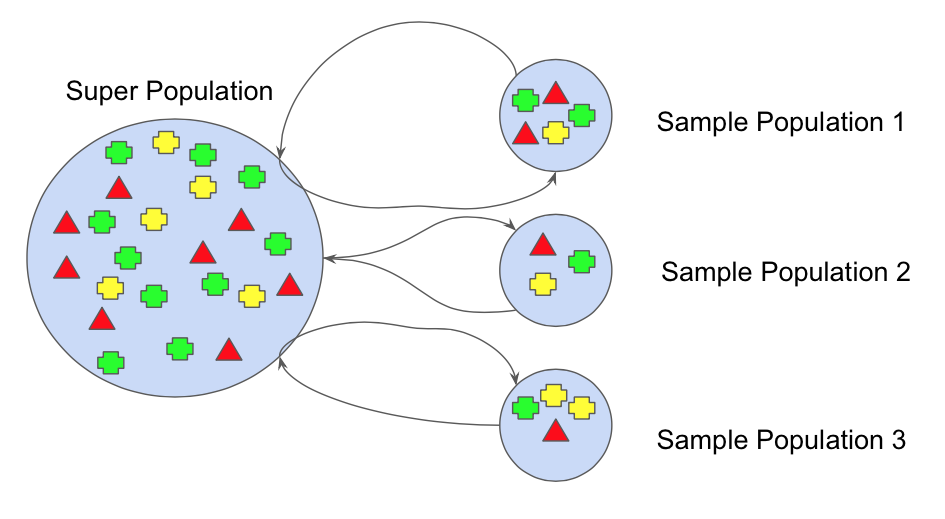
Bootstrapping 방법은 원래 데이터 셋에서 m개의 데이터를 랜덤으로 추출하여 데이터 샘플을 B개 생성합니다.
B개의 데이터 샘플로 각각 B개의 모델을 만들고 Test set은 원래 데이터 셋으로하여 평가를 진행합니다.
그리고 k-fold cross validation과 마찬가지로 얻은 B개의 평가 지표의 평균을 결과로 정합니다.
2. 성능 평가 지표
성능 평가 지표는 회귀 모형과 분류 모형에 따라 달라진다.
(1) 회귀모형의 성능을 평가하는 지표
회귀 모형을 평가하는 지표로는 Sum squared error (SSE), 결정계수, Mean absolute error (MAE), mean absolute percentage error (MAPE)가 있다.
① SSE
SSE는 실제값과 예측값의 차이를 제곱하여 전부 더한 값입니다. 실제로 회귀 모형을 평가 할 때 자주 쓰이는 지표입니다.

② 결정 계수

결정 계수는 선형 회귀 분석의 성능 검증 지표로 많이 이용됩니다. (하지만 선형이 아닌 회귀 모형에서도 사용가능)
결정 계수에 대한 자세한 설명은 통계 카테고리의 회귀분석 파트에서 알려드리도록 하겠습니다.
지금은 단지 결정 계수는 적합한 회귀모형이 실제값을 얼마나 잘 적합하는 지에 대한 비율이라고 생각하시면 됩니다.
③ MAE

MAE는 SSE와 비슷하지만 오차의 제곱이 아닌 오차의 절대값을 평균 낸 값입니다.
④ MAPE

MAPE는 MAE를 계산할 때 실제값에대한 상대적인 비율을 고려하여 계산된 값입니다.
(2) 분류모형의 성능을 평가하는 지표
분류모형의 성능을 평가하는 지표로는 가장 자주 쓰이는 Accuracy, Precision, Recall, Specifity, F1, ROC 곡선을 소개하도록 하겠습니다.
|
Class = {Negative, Positive} |
Predicted class |
||
|
Negative |
Positive |
||
|
Read class |
Negative |
True Negative (TN) |
False Positive (FP) |
|
Positive |
False Negative (FN) |
True Positive (TP) |
|
위의 표는 이진 분류의 혼동 행렬 (Confusion Matrix)를 나타냅니다. 분류모형의 성능은 혼동 행렬을 통해 평가 될 수 있습니다.
① Accuracy

Accuracy는 모든 예측값중에서 실제 값을 맞춘 개수의 비율을 나타냅니다.
② Precision

Precision은 긍정으로 예측한 모든 값중에서 실제값도 긍정인 값의 비율입니다. 즉, 긍정으로 예측할 때 정답일 확률을 나타낸다고 생각하시면 쉬울겁니다.
③ Recall

Recall은 긍정을 맞춘 개수를 정답을 맞춘 개수를 나눈 값으로, 정답중에서 긍정을 맞춘 개수의 비율을 나타냅니다.
④ Specificity

Specificity는 부정을 맞춘 개수를 실제 부정의 개수를 나눈 값으로, 실제 부정중에서 부정으로 예측된 개수의 비율을 나타냅니다.
⑤ F1
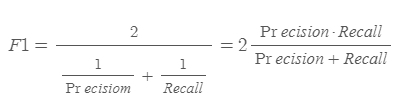
F1 스코어는 Precision과 Recall의 조화 평균을 나타냅니다. F1 스코어는 주로 데이터의 label이 불균형하게 분포할 때 성능 평가 지표로 사용됩니다. 예를 들어서, Positive가 1000개, Negative가 50개 밖에 없다면, 1050개 모두 Positive로 예측해도 Accuracy는 높은 수치를 보이게 됩니다.
하지만 실제로 Negative를 맞추지 못했으니 좋은 모델이 아니겠죠?? 이러한 문제에 대비하여 F1스코어를 사용한다고 생각하시면 됩니다.
⑥ ROC 곡선

ROC 그래프는 가로축을 False Positive Rate (Specificity) 로 하고, 세로축을 TP Rate (Sensitivity) 로 하여 시각화 한 그래프입니다.
그래그가 위로 갈 수록 좋은 모델이라고 해석할 수 있으며, 적어도 y=x 그래프보다 위에 있어야 어느정도 유의미한 모델로 볼 수 있습니다.
'데이터 다루기 > 머신러닝 이론' 카테고리의 다른 글
| [머신러닝] 선형 회귀 분석 (2) (0) | 2019.06.12 |
|---|---|
| [머신러닝] 선형 회귀 분석 (1) (0) | 2019.06.11 |
| Bias & Variance Trade-off (0) | 2019.06.11 |
| Reducible and Irreducible Errors (0) | 2019.06.10 |
| 머신러닝 vs 데이터마이닝 (0) | 2019.06.10 |



